PinnedSimon SpätiLiving Book Data Engineering Design Patterns (DEDP) is live.I Did It. I Published My Book: dataengineeringdesignpatterns.com (or dedp.online, as I like short 😉)Dec 12, 20231Dec 12, 20231
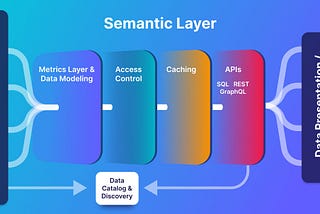
PinnedSimon SpätiThe Rise of the Semantic Layer: Metrics On-The-FlyA semantic layer is a translation layer that sits between your data and your business, converting complex data into business concepts.Nov 21, 20221Nov 21, 20221
PinnedSimon SpätiBuilding a Data Engineering Project in 20 MinutesReal-estates uploaded to S3, Spark & Delta Lake, adding Jupyter notebooks, ingesting to Druid and managing everything with Dagster.Mar 9, 20211Mar 9, 20211
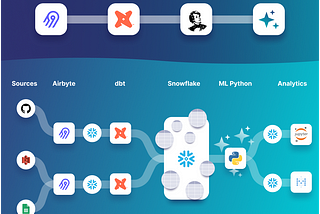
Simon SpätiThe Shift From Data Pipelines to Data ProductsEverything you should know about data orchestration trends, popular frameworks, and the shift to data product graphs in 2022.Jun 20, 2022Jun 20, 2022
Simon SpätiVery nice article.In case of interest, I wrote some lines on why I switched to Obsidian coming from Microsoft OneNote here…Feb 24, 2022Feb 24, 2022
Simon SpätiI find myself, again and again, asking if Rust will be for DE.And on the other hand, it seems that Scala has more ideal tools that suit real fast data wrangling. But as you said, at the end of the day…Feb 5, 20221Feb 5, 20221
Simon SpätiinTowards Data ScienceBuilding an Analytics API with GraphQL: The Next Level of Data Engineering?Having one performant, secure and reliable data endpoint and select the metrics and dimension everybody agrees on.Jan 22, 20221Jan 22, 20221
Simon SpätiThis article is excellent, and I like that you compare Elixir with Scala and Clojure.Jan 22, 2022Jan 22, 2022
Simon SpätiinGeek CultureHow to Take Notes in 2021?Taking notes helps you not to forget things, teaches you to express yourself, brainstorms your thoughts, research a topic, and so many more…Sep 28, 20211Sep 28, 20211